LLM Context Interference Mapping
AbgeschlossenDrei offene Sprachmodelle werden mit kontrollierten Prompt-Paaren (A, B) gefüttert. Gemessen werden Hidden States und Output-Verteilungen, um zu analysieren, wie Modelle komplementäre, widersprüchliche und irrelevante Kontexte überlagern.
Motivation & Kontext
Grosse Sprachmodelle werden typischerweise mit sehr viel Kontext gefüttert – Dokumente, Systemprompts, Tool-Outputs. Intuitiv gehen wir davon aus, dass das Modell diesen Kontext „vernünftig“ mischt. Dieses Experiment untersucht systematisch, wie stark sich die Ausgabe eines Modells verändert, wenn mehrere Kontexte gleichzeitig präsent sind und wie sich diese Interferenz je nach Modell unterscheidet.
Das Experiment ist inspiriert von Arbeiten zu Superposition. Statt nur auf Beispiel-Antworten zu schauen, wird die Geometrie der letzten Hidden States sowie die Token-Logit-Verteilungen analysiert, um nichtlineare Kompositionseffekte sichtbar zu machen.
Experimentaufbau
Es wurden drei offene Modelle untersucht: Mistral-7B-Instruct, Qwen2-7B und Phi-3 Mini. Für jedes Modell wurde ein einheitlicher Datensatz aus Prompt-Paaren (A, B) erstellt, unterteilt in vier Kategorien: komplementär, konfliktiv, kontrolliert (A = B) und irrelevant. Für jedes Paar wurden die letzten Hidden States und die Output-Verteilungen für A, B und die Kombination AB extrahiert. Zusätzlich wurde eine lineare Mischung der Einzelzustände berechnet (), um AB mit einer idealisierten „linearen Komposition“ zu vergleichen.
Hypothesen & Ziele
- •Konflikt-Prompts erzeugen stärkere Interferenz (höhere KL- und L2-Distanzen zwischen AB und der linearen/mischbasierten Baseline) als komplementäre oder kontrollierte Paare.
- •Irrelevante Zusatzkontexte führen zu messbarer, aber systematisch geringerer Interferenz als echte Konflikte.
- •Die Geometrie der Hidden States (z. B. Cosine-Similarity zwischen und ) korreliert mit der Stärke der beobachteten Interferenz auf der Output-Ebene.
- •Verschiedene Modellfamilien zeigen charakteristische Interferenz-Profile – Interferenz ist also nicht nur Prompt-, sondern auch Modell-spezifisch.
Methodologie
Für jedes Prompt-Paar wurden Token-Logit-Verteilungen für die nächste Wortvorhersage in den Zuständen A, B und AB berechnet. Zusätzlich wurde aus den Hidden States ein linearer Referenzzustand konstruiert. Auf dieser Basis wurden KL-Divergenzen und L2-Distanzen zwischen und zwei Baselines ausgewertet: (1) einer linearen Mischung der Logits bzw. Distributionen von A und B, (2) einer unabhängigen „Mix“-Baseline. Die Auswertung erfolgte pro Kategorie und pro Modell sowie über Modelle hinweg (mittlere KL/L2-Werte nach Kategorie).
Visualisierungen & Metriken
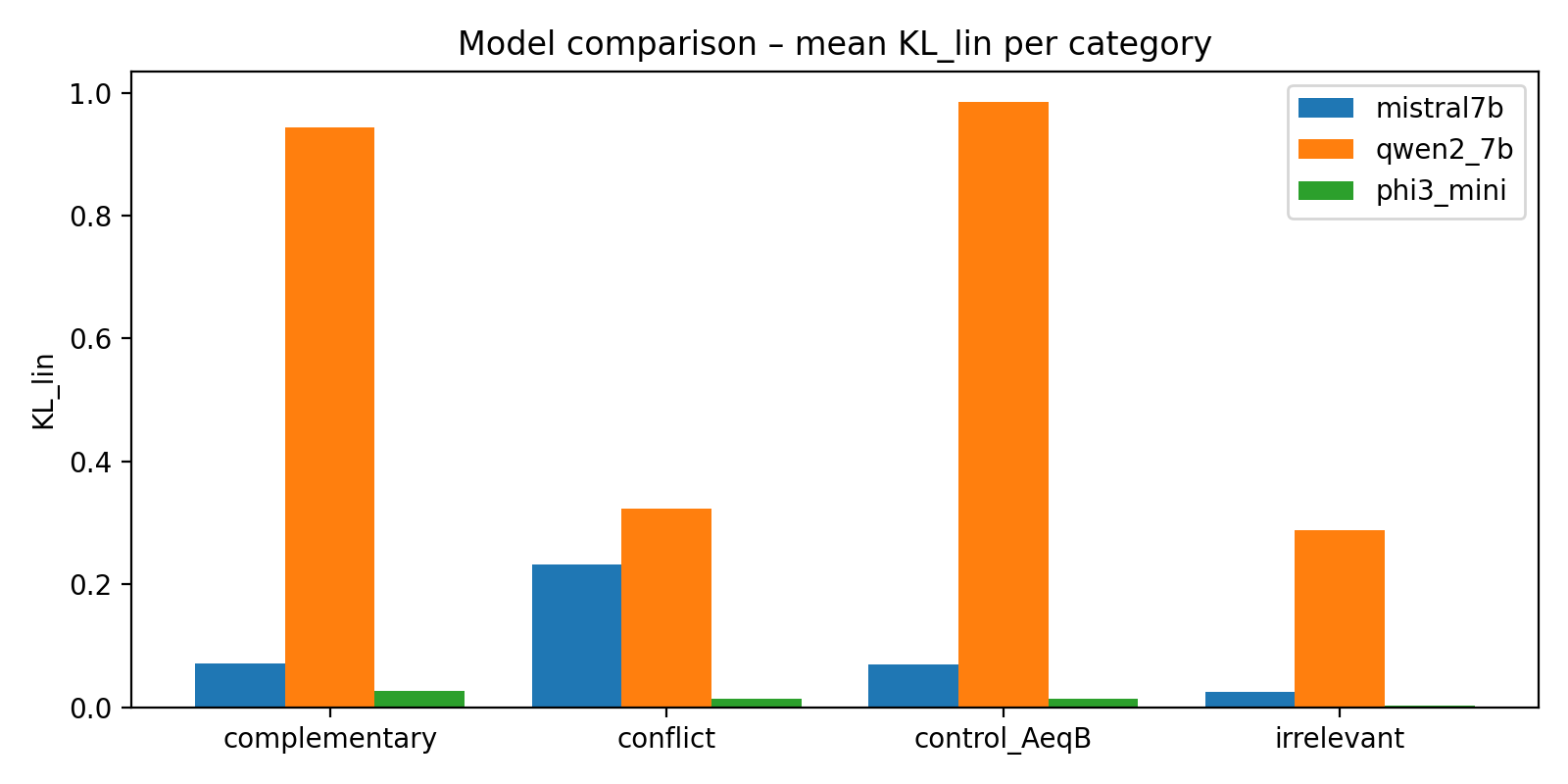
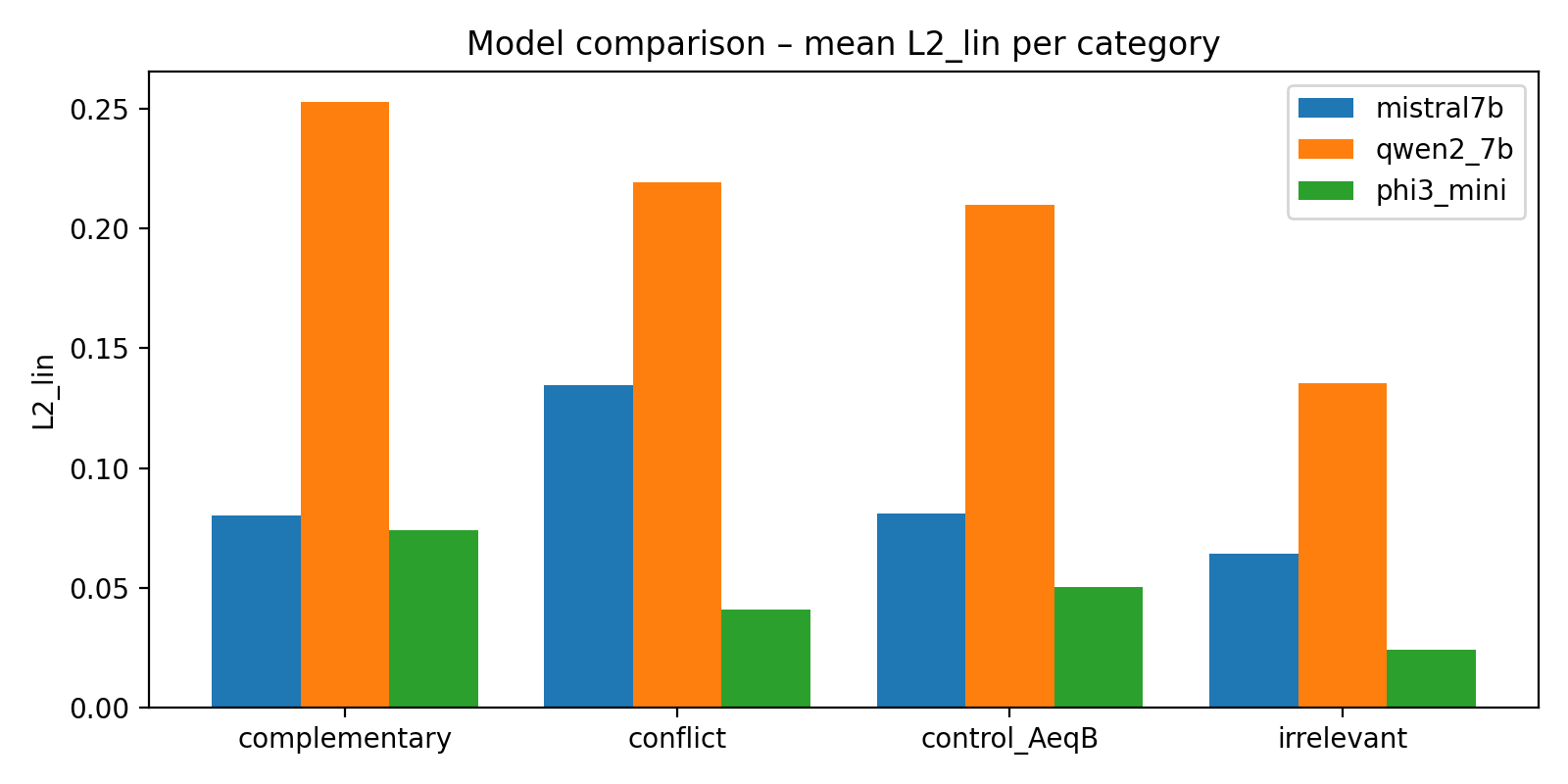
Die Grafiken zeigen, wie stark die Modelle auf unterschiedliche Kontext-Kombinationen reagieren und wie sehr sich die gemeinsame Antwort AB von einer einfachen Mischung der Einzelkontexte A und B entfernt.


Metriken kurz erklärt
- KL-Divergenz: misst, wie stark sich zwei Wahrscheinlichkeitsverteilungen unterscheiden. 0 bedeutet: identisch. Je hoeher der Wert, desto mehr hat sich die Antworttendenz des Modells verschoben.
- L2-Distanz: geometrische Distanz zwischen zwei Verteilungen. Man kann sie sich vorstellen wie die direkte Distanz zwischen zwei Punkten – nur dass die Punkte hier Wahrscheinlichkeitsvektoren sind.
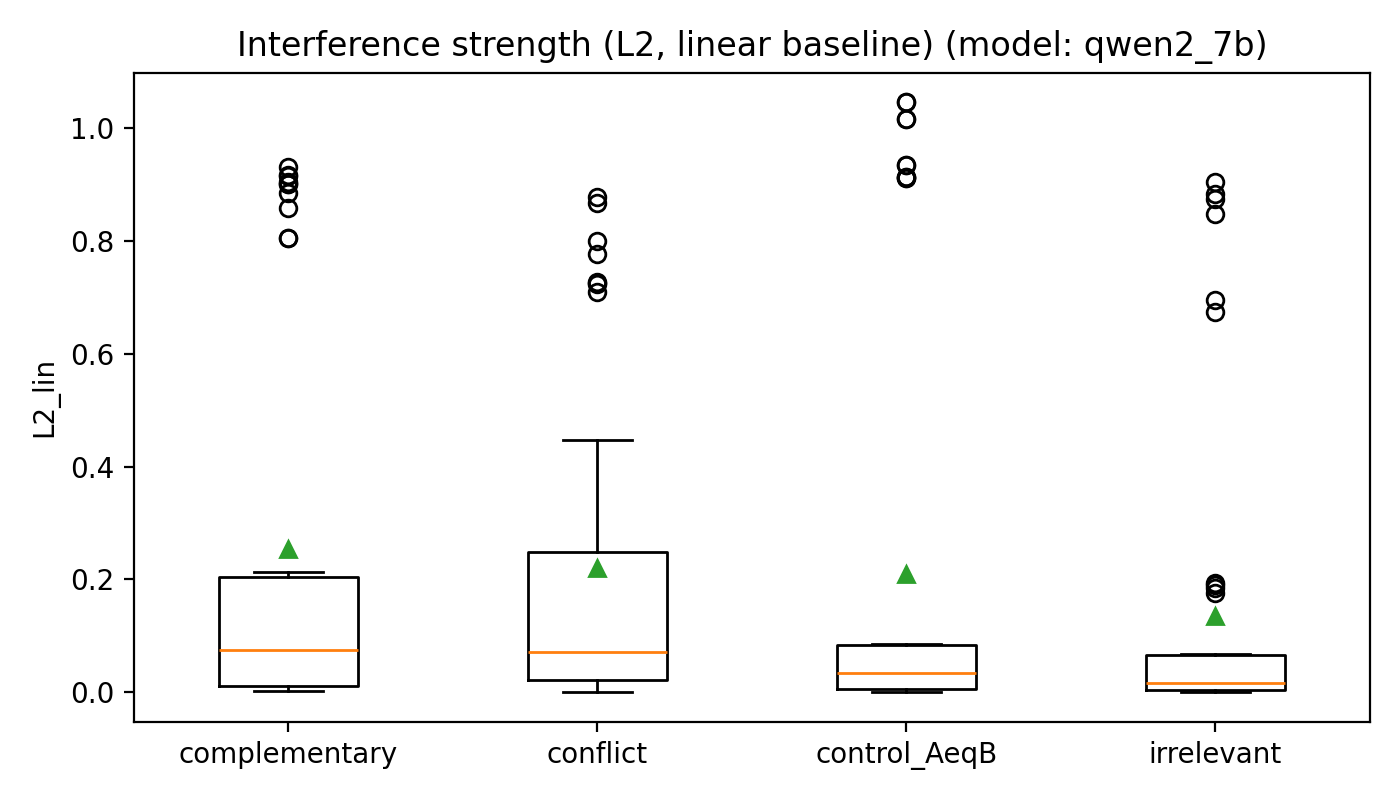
- Boxplots: zeigen nicht nur einen einzelnen Wert, sondern die ganze Verteilung ueber viele Prompt-Paare. So sieht man auf einen Blick typische Werte, Streuung und Ausreisser innerhalb einer Kategorie.
Ergebnisse & Interpretation
Das Experiment zeigt, dass LLMs Kontext nicht einfach linear überlagern. Die kombinierten Zustände AB weichen systematisch von einer idealisierten linearen Mischung der Einzelkontexte ab – sowohl in der Geometrie der Hidden States als auch in den Output-Verteilungen. Die Abweichung wird klar, wenn mit verglichen wird. Die Stärke und Struktur dieser Interferenz ist modellabhängig.
- •Mistral-7B zeigt ein gut interpretierbares Interferenzmuster: Die KL- und L2-Distanzen sind moderat und sortieren sich sinnvoll nach Kategorie (Konflikt > komplementär ≈ irrelevant > Kontrolle A = B). Konflikt-Prompts verschieben die Output-Verteilung deutlich stärker weg von der linearen Baseline als komplementäre Paare.
- •Phi-3 Mini verhält sich fast linear: Die KL- und L2-Werte sind insgesamt klein, AB liegt geometrisch nahe an A und B sowie an der linearen Mischung. Kontext-Überlagerung erzeugt hier nur schwache Interferenz – das Modell scheint Kontexte eher „sanft“ zu mischen.
- •Für Qwen2-7B zeigen sich sehr hohe KL- und L2-Werte (teilweise auch für Kontroll-Prompts) bei gleichzeitig degenerierten Geometrie-Metriken. Das deutet eher auf einen Implementations-/Skalierungs-Mismatch in dieser Messkonfiguration hin als auf ein sinnvolles Interferenzprofil, die Resultate für Qwen2-7B werden daher als explorativ und vorläufig eingeordnet.
- •Über alle Modelle hinweg liegen irrelevante Zusatzkontexte teilweise näher bei Konflikt-Prompts als erwartet. Einfach „noch mehr Kontext anhängen“ ist also nicht neutral: selbst scheinbar irrelevante Informationen können die Verteilung spürbar verschieben.
- •Die Cosine-Similarities der Hidden States sind insgesamt sehr hoch, dennoch zeigen kleine Richtungsänderungen konsistente Effekte auf der Output-Ebene. Das spricht dafür, dass bereits feine geometrische Verschiebungen im letzten Layer semantisch relevante Interferenz repräsentieren.
Status
Technologie-Stack
Key Concepts
Mitmachen
Interesse an diesem Experiment? Diskutiere mit oder trage bei!