Model Priors & Average World
AbgeschlossenFünf offene Sprachmodelle werden mit minimalen, ungeführten Fragen zu menschlichen Attributen konfrontiert. Durch wiederholtes Sampling wird der statistische "Durchschnittsmensch" und die "Durchschnittswelt" rekonstruiert, die in den Modellen kodiert sind.
Motivation & Kontext
Sprachmodelle approximieren eine Wahrscheinlichkeitsverteilung über menschliche Sprache: . Durch wiederholtes Abfragen minimaler Prompts wie "What gender does a typical human being have?" schätzen wir direkt . Dies liefert eine quantitative Messung der impliziten kulturellen und demografischen Defaults, die in den Modellen kodiert sind – der "Durchschnittsmensch" und die "Durchschnittswelt", die das Modell als wahrscheinlichste Annahme hat.
Das Experiment misst nicht reale Bevölkerungsstatistiken. Stattdessen misst es, was das Modell "denkt", wenn es keinen zusätzlichen Kontext erhält – die Maximum-Likelihood-Default-Welt, die in den Gewichten kodiert ist. Dies macht implizite Annahmen explizit und messbar.
Experimentaufbau
Es wurden fünf offene Modelle untersucht: Mistral-7B-Instruct, Llama3-8B, Qwen2-7B, Phi-3 und Gemma2-9B. Für jedes Modell wurden 13 Attribute gemessen: Gender, Hautfarbe, Religion, Alter, Wohnort, Sprache, Beruf, sexuelle Orientierung, Bildungsniveau, wirtschaftlicher Status, politische Orientierung, Familienstatus und Gesundheitsstatus. Für jedes Attribut wurden Ein-Wort-Antworten gesampelt und anschließend manuell kategorisiert, um die Prior-Verteilung zu schätzen.
Hypothesen & Ziele
- •Verschiedene Modelle zeigen unterschiedliche Default-Annahmen für dieselben Attribute, was kulturelle Bias in den Trainingsdaten widerspiegelt.
- •Modelle aus verschiedenen kulturellen Kontexten (z.B. Qwen2 aus China) zeigen charakteristische Bias-Muster, die von westlichen Modellen abweichen.
- •Instruct-Modelle zeigen andere Prior-Verteilungen als Base-Modelle, da Alignment-Training die Defaults verändert.
- •Einige Attribute (z.B. Sprache) zeigen sehr homogene Antworten (starker Default), während andere (z.B. Beruf) diverser sind.
Methodologie
Für jedes Modell und Attribut wurden Ein-Wort-Antworten mit demselben minimalen Prompt gesampelt. Die Antworten wurden in JSON-Format angefordert, um strukturierte Extraktion zu ermöglichen. Anschließend wurden alle Antworten manuell kategorisiert, um semantisch ähnliche Antworten zu gruppieren (z.B. "male" und "männlich"). Die Top-Werte pro Attribut und Modell wurden in einer finalen Zusammenfassung visualisiert.
Visualisierungen & Ergebnisse
Die Visualisierungen zeigen die Top-Werte pro Attribut für jedes Modell. Die Prozentangaben zeigen, wie häufig eine bestimmte Antwort gegeben wurde – höhere Werte bedeuten stärkere Default-Annahmen.
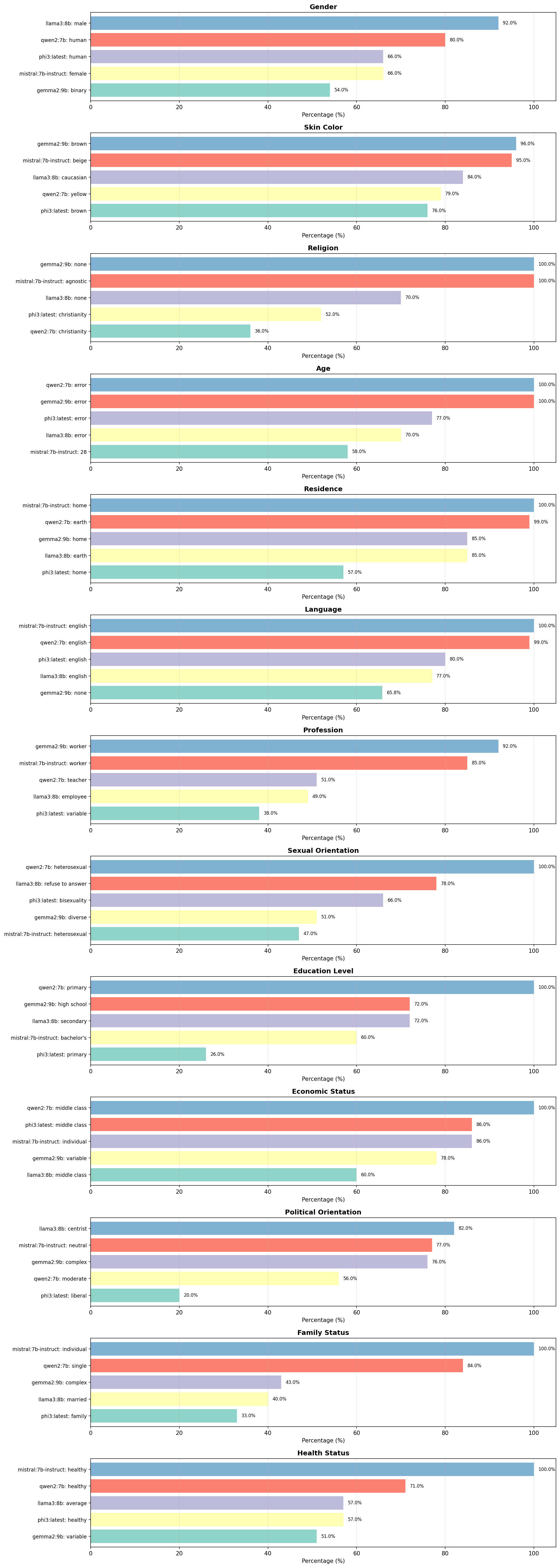













Ergebnisse & Interpretation
Das Experiment zeigt deutliche kulturelle Bias-Muster in allen getesteten Modellen. Die stärksten Defaults sind bei Sprache (fast alle Modelle → "english", 77-100%) und Hautfarbe (kulturell geprägt: Qwen2 → "yellow" 79%, westliche Modelle → "beige/caucasian" 84-95%) sichtbar. Besonders auffällig sind auch die sexuelle Orientierung (Qwen2: 100% heterosexual, Phi3: 66% bisexuality) und Religion(Mistral/Gemma2: 100% nicht-religiös, Qwen2/Phi3: 36-52% christianity). Modelle aus verschiedenen kulturellen Kontexten zeigen charakteristische Unterschiede, was die Bedeutung von diversen Trainingsdaten unterstreicht.
- •Kulturelle Bias ist messbar: Qwen2 (chinesisches Modell) zeigt asiatische Defaults ("yellow" für Hautfarbe, 79%), während westliche Modelle kaukasische Defaults bevorzugen (Mistral: 95% "beige", Llama3: 84% "caucasian"). Gemma2 und Phi3 zeigen "brown" (76-96%), was eine andere Perspektive darstellt. Dies zeigt, dass Trainingsdaten die impliziten Annahmen stark prägen.
- •Gender-Bias variiert stark: Llama3 zeigt einen sehr starken männlichen Bias (92% "male"), während Mistral einen weiblichen Default hat (66% "female"). Qwen2 und Phi3 weichen der Frage aus ("human", 66-80%), während Gemma2 abstrakt antwortet ("binary", 54%).
- •Sprach-Bias ist universell: Fast alle Modelle antworten mit "english" (77-100%), was den starken anglophonen Bias in den Trainingsdaten widerspiegelt. Nur Gemma2 weicht aus (66% "none").
- •Sexuelle Orientierung zeigt extreme Defaults: Qwen2 zeigt einen sehr starken heteronormativen Bias (100% "heterosexual"), während Phi3 überraschenderweise "bisexuality" bevorzugt (66%). Llama3 weicht der Frage aus (78% "refuse to answer"), was zeigt, dass Alignment-Training die Antworten beeinflusst.
- •Religion: Nicht-religiös vs. christlich: Mistral und Gemma2 bevorzugen nicht-religiöse Antworten (100% "agnostic"/"none"), während Qwen2 und Phi3 christliche Defaults zeigen (36-52% "christianity"). Llama3 liegt dazwischen (70% "none").
- •Technische Herausforderungen: JSON-Parsing für numerische Werte funktionierte nur bei Mistral zuverlässig (58% → 28 Jahre). Andere Modelle produzierten 70-100% "error"-Antworten beim Alter, was zeigt, dass strukturierte Ausgaben nicht trivial sind.
- •Neue Attribute zeigen interessante Muster: Bei Bildungsniveau zeigen sich klare Unterschiede (Mistral: 60% "bachelor's", Qwen2: 100% "primary"). Bei wirtschaftlichem Status bevorzugen die meisten Modelle "middle class" (60-100%).Politische Orientierung ist fragmentiert, aber Llama3 zeigt 82% "centrist". Familienstatus variiert stark (Mistral: 100% "individual", Qwen2: 84% "single").
- •Modell-spezifische Muster: Mistral ist am ausgewogensten und technisch zuverlässigsten. Llama3 zeigt starke Bias, aber auch viele "no answer"-Antworten bei sensiblen Themen. Qwen2 zeigt kulturelle Charakteristika, aber auch sehr starke Defaults (100% heterosexual, 100% primary education). Gemma2 antwortet oft abstrakt ("complex", "variable", "diverse").
Status
Technologie-Stack
Key Concepts
Mitmachen
Interesse an diesem Experiment? Diskutiere mit oder trage bei!