Kontext-Interferenz: Warum "Mehr Kontext" ein LLM sabotieren kann
Das Experiment "LLM Context Interference Mapping" zeigt, wie sich Konflikte und irrelevanter Kontext nicht-linear auf die Ausgaben von Mistral-7B, Qwen2-7B und Phi-3 Mini auswirken – und was das für gutes Prompt-Design bedeutet.
Die dunkle Seite des Multi-Tasking
Wir füttern Large Language Models (LLMs) ständig mit Kontext: System-Anweisungen, Dokumente, Chat-Verläufe. Intuitiv gehen wir davon aus, dass das Modell diese Informationen sinnvoll „mischt“. Aber was passiert, wenn sich diese Informationen widersprechen oder einfach nur unnötig sind?
Das Experiment „LLM Context Interference Mapping“ hat systematisch untersucht, wie die versteckten Zustände und die Ausgabeverteilungen (Token Logits/Wahrscheinlichkeiten) von LLMs reagieren, wenn sie gleichzeitig zwei Kontexte (A und B) erhalten. Das Ziel: Kontextinterferenz sichtbar und über verschiedene Modelle hinweg vergleichbar zu machen.
Ich suchte nach nicht-linearen Kompositionseffekten – also jenen Momenten, in denen die kombinierte Antwort p_AB nicht einfach die mathematische Summe der Einzelantworten p_A und p_B ist. Gemessen wurde diese Abweichung hauptsächlich durch die KL-Divergenz (KL_lin) und die L2-Distanz im Vergleich zu einer linearen Baseline.
Vier Kategorien von Kontext
Für das Experiment wurden drei populäre offene Modelle – Mistral-7B-Instruct, Qwen2-7B-Instruct und Phi-3 Mini – mit Prompt-Paaren in vier Kategorien konfrontiert:
- Conflict (Konflikt): Kontexte, die sich widersprechen.
- Complementary (Komplementär): Kontexte, die sich gegenseitig unterstützen.
- Control (Kontrolle): A und B sind ungefähr gleich (AeqB) – hier sollte die Interferenz idealerweise gering sein.
- Irrelevant: Zusätzlicher Kontext, der keine Rolle spielen sollte.
Drei Modelle, Drei Profile der Interferenz
Die Analyse zeigte, dass jedes Modell Kontexte auf völlig unterschiedliche Weise „mischt“ und somit einzigartige Interferenzprofile aufweist.
1. Mistral-7B-Instruct: Der Empfindliche Mischer
Mistral-7B-Instruct zeigte ein klares und interpretierbares Interferenzprofil.
- Der Konflikt-Effekt: Prompts der Kategorie Conflict erzeugten die grössten Abweichungen (grosse
KL_lin- und L2-Distanzen) von der linearen Vorhersage. Der mittlereKL_lin-Wert war bei conflict deutlich am höchsten. - Bestätigte Linearität: Die Kontroll-Prompts (control_AeqB) blieben wie gewünscht nahe an der Baseline.
2. Phi-3 Mini: Der Sanfte Lineare
Phi-3 Mini verhielt sich in dieser Konfiguration fast linear.
- Milde Interferenz: Phi-3 Mini zeigte über alle Kategorien hinweg die niedrigsten
KL_lin-Werte. - Schlussfolgerung: Dieses Modell mischt Kontexte relativ „sanft“; die kombinierte Ausgabe ist sehr gut durch die einfache Kombination der Einzelausgaben vorhersagbar.
3. Qwen2-7B-Instruct: Der Instabile Aussenseiter
Qwen2-7B-Instruct zeigte ungewöhnlich hohe Interferenzwerte.
- Extreme Abweichung: Die
KL_lin-Werte waren extrem hoch, und das sogar bei Kontroll-Prompts (control_AeqB). - Hinweis: Diese Ergebnisse werden als exploratorisch und vorläufig eingestuft, da sie möglicherweise auf Konfigurationsprobleme hindeuten könnten, aber sie zeigen die potenzielle Instabilität mancher Modelle bei Multi-Kontext-Eingaben.
KL-Interferenz über Modelle
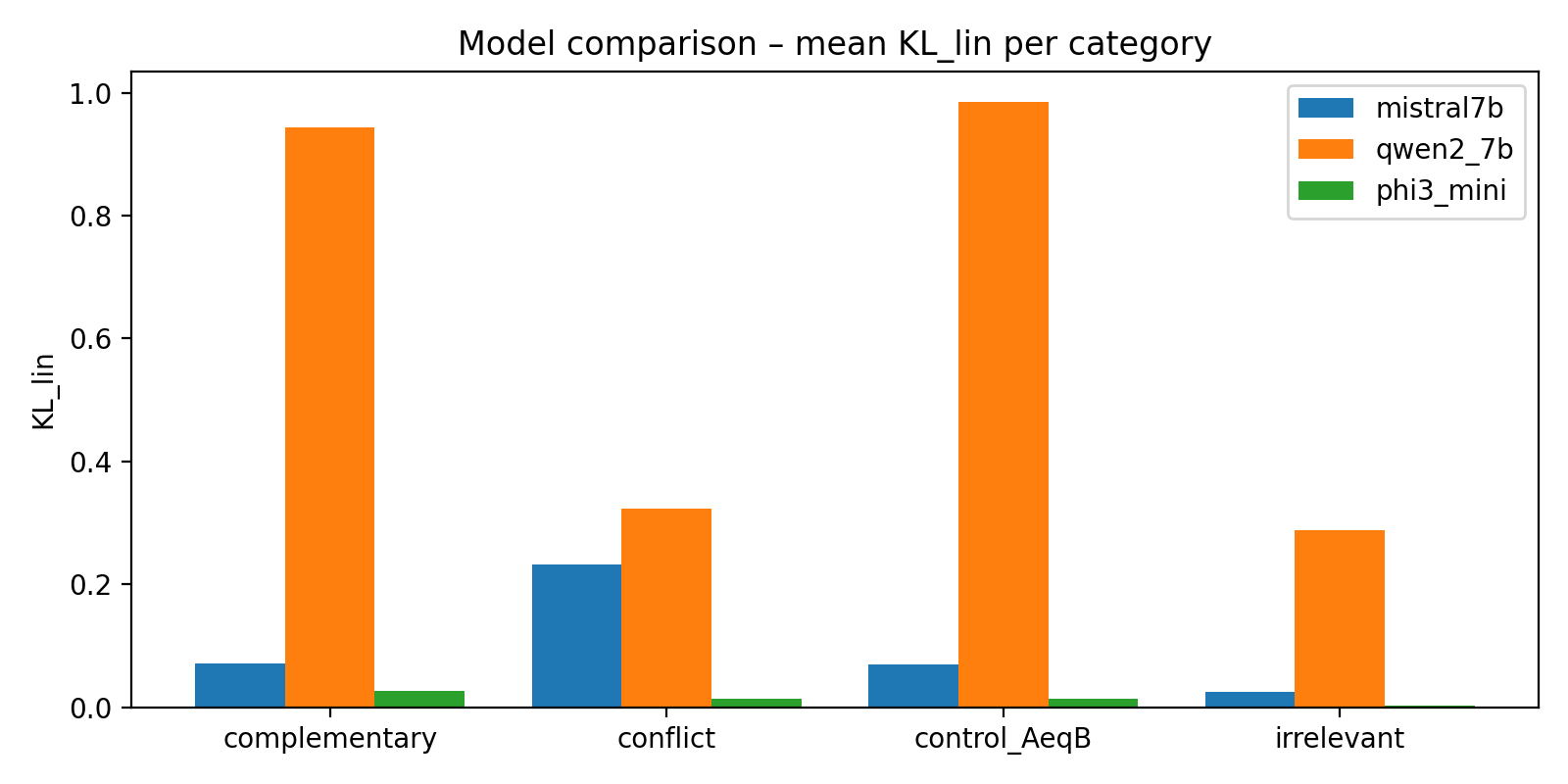
KL_lin über alle Modelle und Kategorien.
Hohe Balken markieren starke Abweichungen von der linearen Baseline – also starke Kontext-Interferenz.
Wichtige Schlussfolgerungen für den LLM-Nutzer: Qualität vor Quantität
Die Ergebnisse bestätigen, dass mehr Kontext nicht automatisch bessere oder stabilere Ergebnisse liefert. Nutzer können die Qualität ihrer Prompts verbessern, indem sie die Art der Interferenz berücksichtigen:
1. Vermeidung von Konflikten
Die grösste Gefahr geht von widersprüchlichen Informationen oder Anweisungen aus. Da Conflict-Prompts die höchste Nicht-Linearität verursachen, gilt:
- Praktische Konsequenz: Beim Kombinieren von Anweisungen A und B ist darauf zu achten, dass diese nicht im Widerspruch stehen. Wenn sich ein Modell wie Mistral-7B-Instruct stark von der Baseline entfernt, bedeutet dies, dass die Ausgabe unvorhersehbar wird und nicht mehr leicht aus der Summe der Teile abgeleitet werden kann.
2. Irrelevanter Kontext ist kein Platzhalter
Die Kategorie irrelevant zeigte, dass zusätzlicher, unwesentlicher Kontext nicht immer neutral ist.
- Praktische Konsequenz: Das einfache Hinzufügen von mehr Kontext kann messbare Nebenwirkungen haben, da es die Ausgabeverteilung verschiebt. Prompts sollten regelmässig gesäubert und unnötige Dokumentausschnitte entfernt werden, um die Wahrscheinlichkeit unvorhergesehener Interferenzen zu reduzieren.
3. Die Geometrie zählt
Die Analyse der versteckten Zustände zeigte, dass selbst wenn die Zustände in den letzten Schichten sehr ähnlich erscheinen, kleine direktionale Verschiebungen in der Geometrie systematisch mit den beobachteten, signifikanten Änderungen in der Ausgabeverteilung verbunden sind.
- Schlussfolgerung: Die Art der Interferenz ist tief im Modell kodiert, und feinkörnige geometrische Unterschiede in der letzten Schicht können semantisch relevante Interferenz erzeugen.
Fazit
Wenn man LLMs nutzt, um komplexe Aufgaben zu lösen, ist es entscheidend, den Kontext aktiv zu managen. Die Wahl des Modells spielt eine Rolle.
Der beste Ansatz ist, Prompts zu bereinigen, Konflikte zu vermeiden und nur wirklich relevanten Kontext zu liefern. Dadurch wird die Wahrscheinlichkeit, dass das LLM den Kontext auf eine Weise kombiniert, die näher an der vorhersagbaren linearen Baseline liegt, erhöht.